Even small to medium size websites may references hundreds of pages, scripts, images, music files and other web ("mime") documents. Finding broken or out-of-date links is difficult and time-consuming. SiteVerify reads all the pages below a given URL, parses them and locates the components referenced by them. Any errors are listed clearly.
SiteVerify will not, of course, exercise data-driven web sites. It is intended for verification of the static components of general web sites.
After starting the program, enter the URL you want to check in the "URL to verify" field. Then choose "Run" from the "Actions" menu.
SiteVerify is multi-threaded, which means that it will use several processes to analyze your web site as quickly as possible.
By default, SiteVerify only parses and analyzes HTML pages that are at or beneath the URL given. External web pages are just checked for existence only. This can be overridden; see the Options described below.
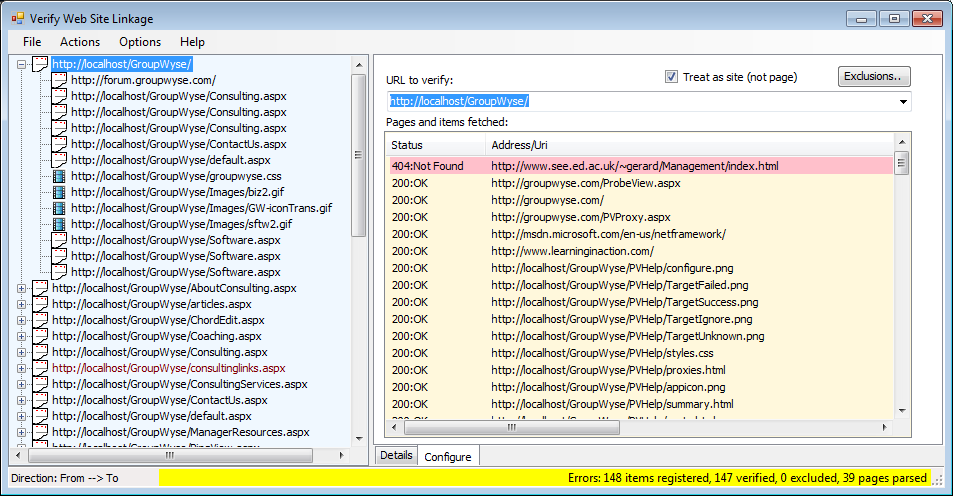
When SiteVerify has completed its analysis, the left-hand list will be filled with every link mentioned in any page.
These results are organized in one of two ways:
The organization can be changed using the "Display Links Forward" option (see below).
Each entry has a icon indicating the media ("mime") type or an error icon if not found or the item fails to parse.
The status bar indicates the direction of the link display.
This text bar at the bottom of the window indicates the link display direction and the current status of the scan.
The right-hand tabbed section contains the configuration information and the details of the currently selected link in the link list.
When you select a link in the link list, its details are shown in this panel. If you've selected to preserve the parsed text, the text of the HTML page is displayed, also.
The Configuration tab contains the URL you want to search along with other configuration controls.
This is where you enter the URL of the web site you want to scan.
If you've entered the name of a specific page, clear this check box.
Clicking this button brings up a dialog that allows you to exclude certain items from analysis.
The items in the list below are updated dynamically as SiteVerify opens and parses the HTML pages you've selected.
This menu item saves the results of the last scan as a "comma-separated variable" (CSV) file that can be imported into Excel.
This menu item terminates the program.
This menu item discards any prior scan results.
This menu item starts the analysis process for the currently specified URL.
This menu item stops the analysis process as quickly as possible. Unfinished results are termed "incomplete".
When checked, the links are displayed by originating page, with each immediate referenced link as a sub-item.
When unchecked, the links are displayed by terminating target, with every refering page treated as a sub-item.
Items (pages) that are excluded are usually not displayed, either as source or target links. This option shows excluded links.
This option removes all incomplete results. Incomplete results are those which were queued for processing when the user stopped the scan.
This option shows incomplete items.
This option causes all the parsed HTML to be preserved as large blocks of text. These text blocks are displayed in the detailed link information when a page link is selected.
This option is usually checked, which causes links to be compare as "case-insensitive". That is, differences between upper and lower case letters are ignored.
You may uncheck this option if your website uses a file system that is case-sensitive. Some OSX and most Linux file systems are case-sensitive.
SiteVerify tries to enforce nominal correctness in HTML pages. Unclosed tags, for example, are considered as parsing errors. If you want to ignore such errors in parse pages you should check this option.
This option prevents causes SiteVerify from parsing pages which do not appear to belong as sub-elements to the current URL.
This option clears the history of URLs you have analyzed.
This option allows you to set the number of worker threads being used to fetch and parse web pages. The default setting of 5 is sufficient for most dual-processor machines with normal bandwitdh connections. If you have a very fast machine or connection, you may want to increase this number.
This option controls the number of links traversed by SiteVerify during analysis. If this number is exceeded the analysis is terminated.
The goal of this option is to prevent SiteVerify from unintentionally running for a long time.
This option shows the help pages.
This option displays a dialog box giving details about your version of SiteVerify.
The term 'exclusion' refers to a string value that is matched against every target link processed. If the string matches, the link is ignored.
A normal (non-RegEx) exclusion is a string that is matched, either considering or ignoring case, to any target that is about to be fetched.
A regular expression exclusion is a pattern-matching string that is matched to any link before the link is processed. If the match is successful the link is excluded.
For more information about Microsoft .Net Regular Expressions, see the .Net documentation at Microsoft.com and other sources.